Replicate APIとAWSを使った生成AI画像の保存
このブログ記事では、ReplicateのAPIを使用してコマンドラインからAI生成画像を作成する方法を紹介します。また、webhook.siteを使ってWebhook通知を検証する方法や、AWSのLambda、API Gateway、S3を使って生成された画像を保存する方法についても説明します。それでは始めましょう!
1. コマンドラインでのReplicate APIの設定と実行
Windows WSL ubuntu 環境 からcurl で実行しました。リクエストを認証するためにReplicateからAPIキーを取得する必要があります。
https://replicate.com/account/api-tokens
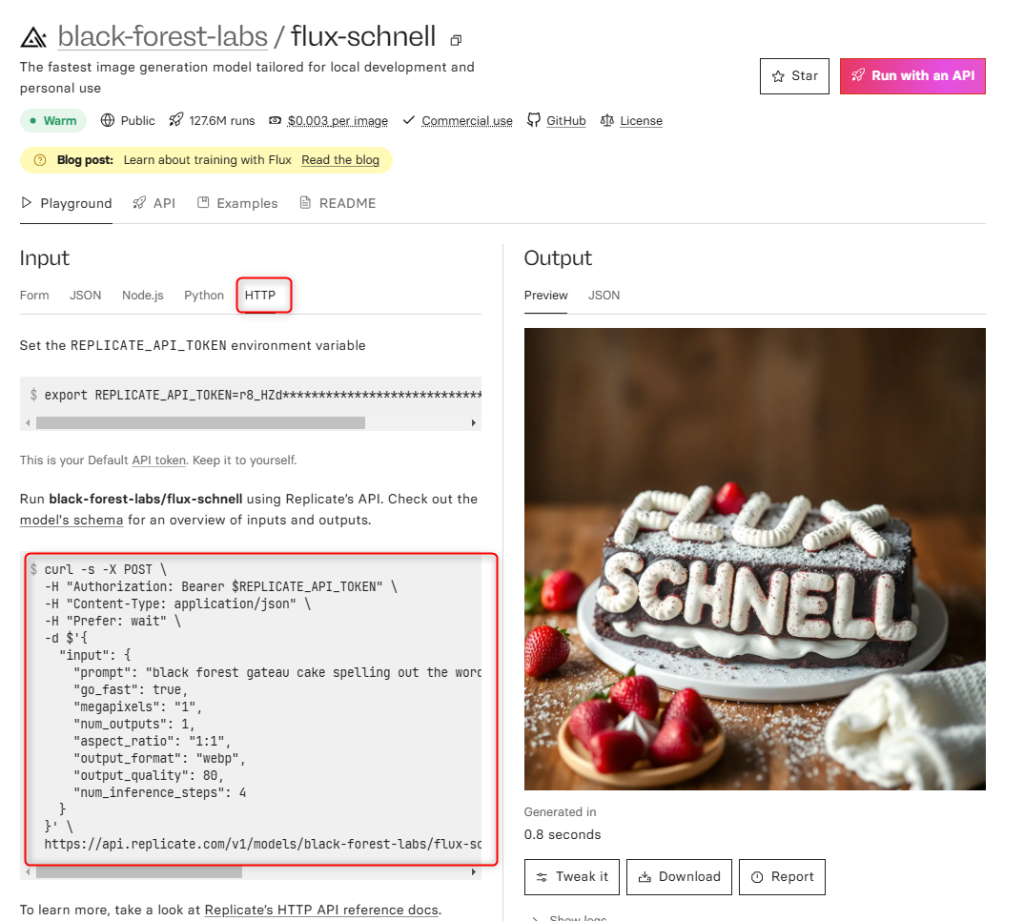
以下は flux-schnell 画像生成リクエストをcurl コマンドで実行する例です:
curl -X POST \
-H "Authorization: Bearer $YOUR_REPLICATE_API_KEY" \
-H "Content-Type: application/json" \
-H "Prefer: wait" \
-d '{
"input": {
"prompt": "flying cat",
"go_fast": true,
"megapixels": "1",
"num_outputs": 1,
"aspect_ratio": "1:1",
"output_format": "jpg",
"output_quality": 80,
"num_inference_steps": 4
}
}' \
https://api.replicate.com/v1/models/black-forest-labs/flux-schnell/predictions$YOUR_REPLICATE_API_KEYを実際のAPIキーに、入力のpromptは、生成したい画像を入力してください。 curl コマンドの実行パラメータは、WEBのモデル画面の HTTP タブに表示されています。実行結果は、replicate の Dashboardから確認できます。
2. webhook.siteを使ったWebhookレスポンスの確認
画像が準備できたときに通知を受け取るために、Webhookを使用します。webhook.siteのようなサービスを使うと、受信するHTTPリクエスト用の一時的なURLを簡単に取得できます。
Webhookを設定する手順:
- webhook.siteにアクセスします。
- 提供された一意のURLをコピーします。
- このURLを以下のようにReplicate APIリクエストに含めます:

curl -X POST \
-H "Authorization: Bearer $YOUR_REPLICATE_API_KEY" \
-H "Content-Type: application/json" \
-H "Prefer: wait" \
-d '{
"input": {
"prompt": "grin like a Cheshire cat",
"go_fast": true,
"megapixels": "1",
"num_outputs": 1,
"aspect_ratio": "1:1",
"output_format": "jpg",
"output_quality": 80,
"num_inference_steps": 4
},
"webhook": "https://webhook.site/your_id",
"webhook_events_filter": ["completed"]
}' \
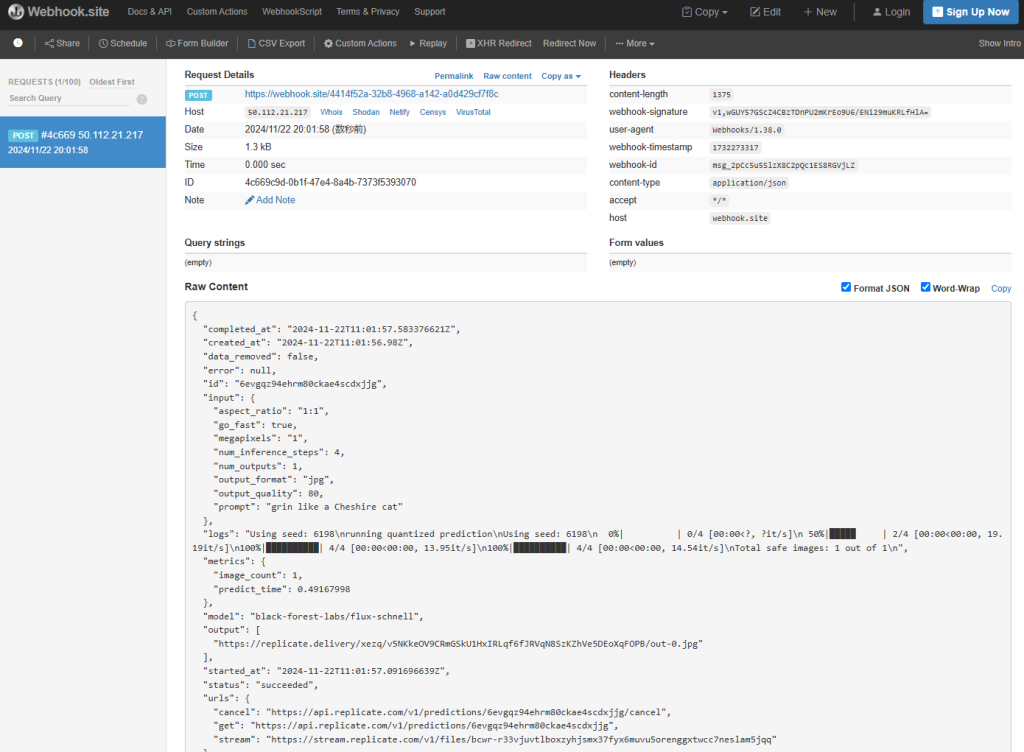
https://api.replicate.com/v1/models/black-forest-labs/flux-schnell/predictions 予測が完了すると、ReplicateはWebhook URLにリクエストを送信し、webhook.siteでAPIレスポンス全体を確認できます。これはデバッグやAPIレスポンスの構造を理解するのに便利です。
以下は、Webhookの結果として受け取ったJSONの例です:
{
"completed_at": "2024-11-22T11:01:57.583376621Z",
"created_at": "2024-11-22T11:01:56.98Z",
"data_removed": false,
"error": null,
"id": "6evgqz94ehrm80ckae4scdxjjg",
"input": {
"aspect_ratio": "1:1",
"go_fast": true,
"megapixels": "1",
"num_inference_steps": 4,
"num_outputs": 1,
"output_format": "jpg",
"output_quality": 80,
"prompt": "grin like a Cheshire cat"
},
"logs": "Using seed: 6198\nrunning quantized prediction\nUsing seed: 6198\n 0%| | 0/4 [00:00<?, ?it/s]\n 50%|█████ | 2/4 [00:00<00:00, 19.19it/s]\n100%|██████████| 4/4 [00:00<00:00, 13.95it/s]\n100%|██████████| 4/4 [00:00<00:00, 14.54it/s]\nTotal safe images: 1 out of 1\n",
"metrics": {
"image_count": 1,
"predict_time": 0.49167998
},
"model": "black-forest-labs/flux-schnell",
"output": [
"https://replicate.delivery/xezq/v5NKkeOV9CRmGSkU1HxIRLqf6fJRVqN8SzKZhVe5DEoXqFOPB/out-0.jpg"
],
"started_at": "2024-11-22T11:01:57.091696639Z",
"status": "succeeded",
"urls": {
"cancel": "https://api.replicate.com/v1/predictions/6evgqz94ehrm80ckae4scdxjjg/cancel",
"get": "https://api.replicate.com/v1/predictions/6evgqz94ehrm80ckae4scdxjjg",
"stream": "https://stream.replicate.com/v1/files/bcwr-r33vjuvtlboxzyhjsmx37fyx6muvu5orenggxtwcc7neslam5jqq"
},
"version": "dp-4d0bcc010b3049749a251855f12800be",
"webhook": "https://webhook.site/4414f52a-32b8-4968-a142-a0d429cf7f8c",
"webhook_events_filter": [
"completed"
]
}
3. AWS Lambda、API Gateway、S3を使った生成画像の保存
次に、ReplicateのWebhookから返された画像URLを使用して、AWS LambdaとAPI Gatewayを使ってAmazon S3バケットに自動的に保存します。
ステップ1: Lambda関数の作成
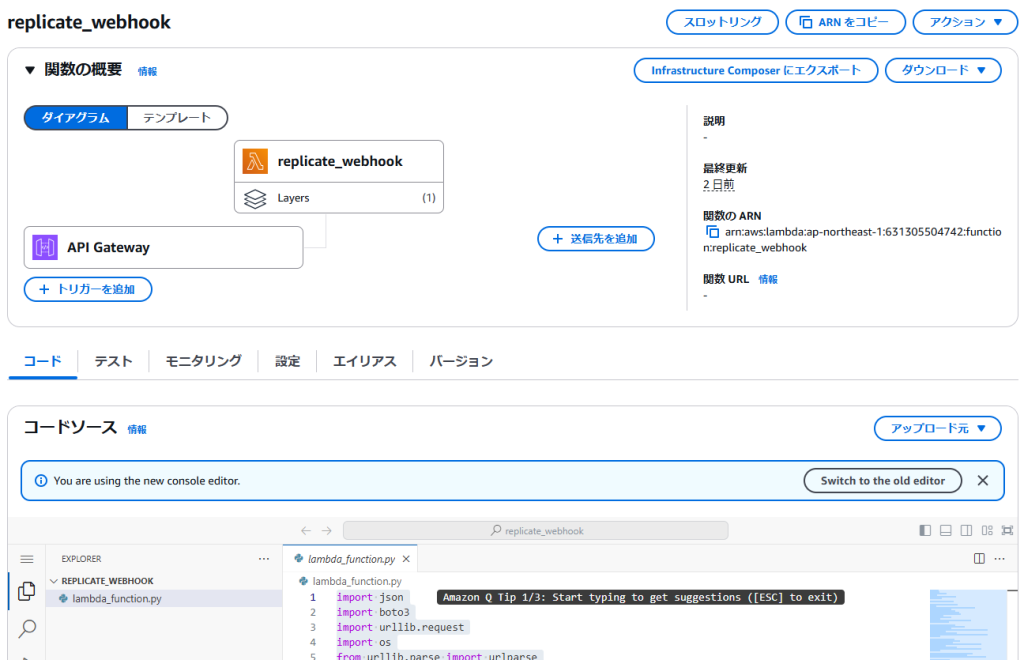
- AWSコンソールでAWS Lambdaにアクセスします。
replicate_webhookという名前の新しい関数を作成します。- requestはディフォルトライブラリに含まれていないので レイヤーを追加してください。
https://github.com/keithrozario/Klayers に有志の提供してくれている、レイヤーの arn リストがあります。Python の Lambda レイヤーを公開・管理しているリポジトリです。
今回利用したのは、以下のレイヤです。
python3.10 arn:aws:lambda:ap-northeast-1:770693421928:layer:Klayers-p310-requests:16 - 以下のPythonコードを使用して、画像をS3に保存します:
import json
import boto3
import urllib.request
import os
from urllib.parse import urlparse
s3_client = boto3.client('s3')
def lambda_handler(event, context):
try:
# Webhook からのイベントが API Gateway 経由の場合
if 'body' in event:
body = event['body']
if isinstance(body, str):
data = json.loads(body)
else:
data = body
else:
# 直接 JSON がイベントとして渡された場合
data = event
# 必要なフィールドの取得
output_urls = data.get('output', [])
if not output_urls:
print("Webhook ペイロードに output URL が含まれていません。")
return {
'statusCode': 400,
'body': json.dumps('output URL が見つかりませんでした。')
}
# 'id' フィールドの取得
prediction_id = data.get('id')
if not prediction_id:
print("Webhook ペイロードに id が含まれていません。")
return {
'statusCode': 400,
'body': json.dumps('id が見つかりませんでした。')
}
# 環境変数から S3 バケット名とベースパスを取得
S3_BUCKET = os.environ.get('S3_BUCKET')
S3_BASE_PATH = os.environ.get('S3_BASE_PATH', '') # オプション
if not S3_BUCKET:
print("環境変数 S3_BUCKET が設定されていません。")
return {
'statusCode': 500,
'body': json.dumps('内部サーバーエラー。')
}
# 各 URL に対して処理を実行
for url in output_urls:
try:
# ファイルをダウンロード
response = urllib.request.urlopen(url)
file_content = response.read()
# URL からファイル名を抽出
parsed_url = urlparse(url)
file_name = os.path.basename(parsed_url.path)
# S3 のキー(パス)を定義
# 'id' を含めたパスを作成
if S3_BASE_PATH:
s3_key = f"{S3_BASE_PATH}/{prediction_id}/{file_name}"
else:
s3_key = f"{prediction_id}/{file_name}"
# S3 にアップロード
s3_client.put_object(
Bucket=S3_BUCKET,
Key=s3_key,
Body=file_content,
ContentType=response.headers.get_content_type()
)
print(f"ファイル {file_name} を s3://{S3_BUCKET}/{s3_key} にアップロードしました。")
except Exception as e:
print(f"URL {url} の処理中にエラーが発生しました: {e}")
# 必要に応じてリトライや詳細なログ記録を追加可能
return {
'statusCode': 200,
'body': json.dumps('ファイルの処理が完了しました。')
}
except Exception as e:
print(f"イベント処理中にエラーが発生しました: {e}")
return {
'statusCode': 500,
'body': json.dumps('内部サーバーエラー。')
}
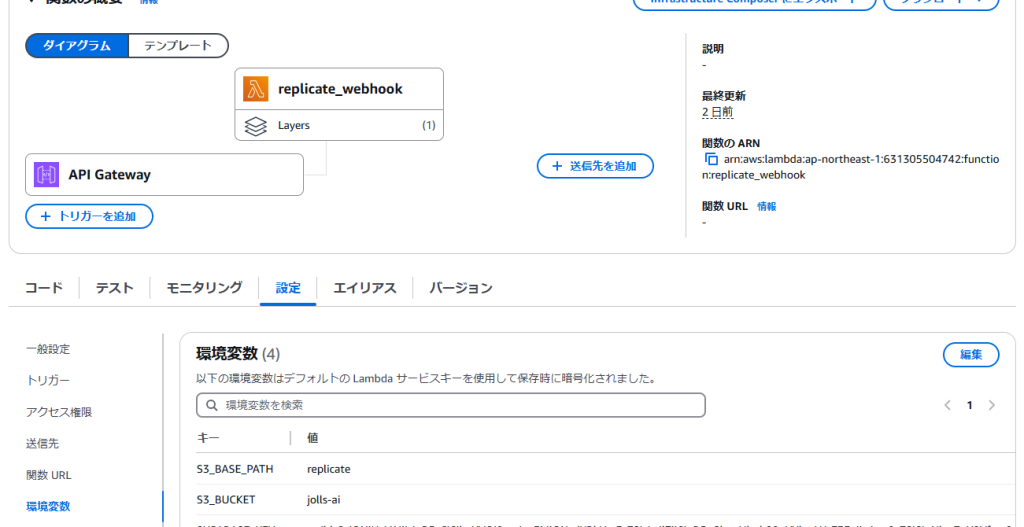
lambda の設定画面で 'S3_BUCKET', "S3_BASE_PATH' の環境変数を設定してください。
さらに、利用するS3バケットの書き込み権限を与えてください。
ステップ2: API Gatewayの設定
- AWS API Gatewayにアクセスし、新しいREST APIを作成します。
- Lambda関数をトリガーする
POSTエンドポイントを設定します。 - APIをデプロイし、呼び出しURLをメモします。
ステップ3: Webhook URLの更新
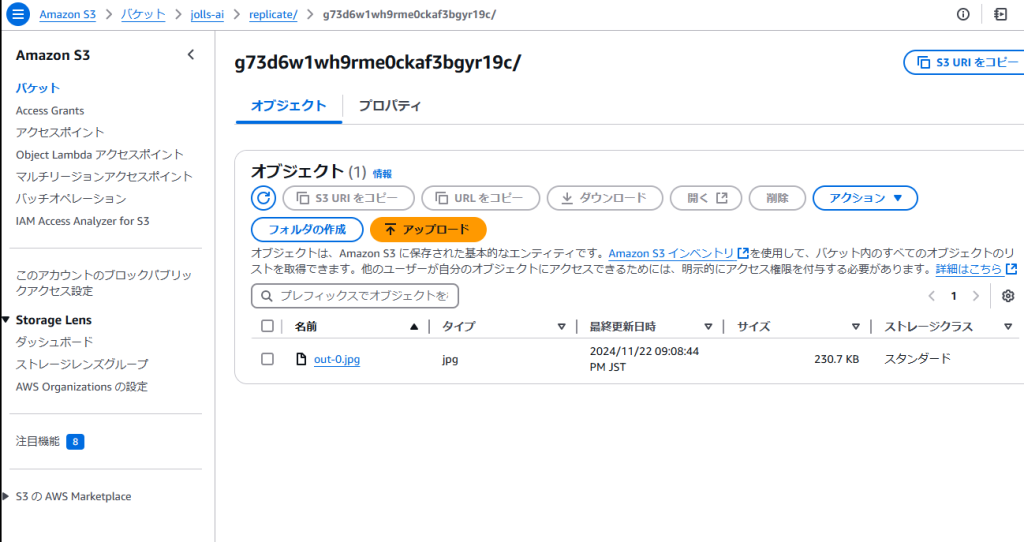
Replicate APIのWebhookをAPI Gatewayの呼び出しURLに更新します。これにより、画像の生成が完了すると、WebhookリクエストがLambda関数をトリガーし、画像がS3に保存されます。
まとめ
ReplicateのAPI、webhook.site、AWSサービスを組み合わせることで、AI生成コンテンツの生成、管理、保存のための強力なワークフローを構築できます。LambdaとS3の組み合わせにより、手動での介入が不要なシームレスな自動化が可能になります。
次回は、supabase を利用して、生成した画像をDBに登録するコードを lambda に追加します。
Follow me!
