Cogを使って Replicate に SD1.5をPUSH
Cogを利用して Replicate に diffusers SD1.5をモデルをPUSHし、Replicate で画像を生成してみました。Cogは機械学習モデルを標準的なコンテナとしてパッケージ化するオープンソースツールであり、Replicateでの共有や利用に最適です。
前提条件
- Dockerがインストールされて動作していること
- Replicateのアカウントがあること
- Windowsの場合、WSL上でUbuntuを利用していること
環境設定
Cogのインストール
WSL の Linux で下記のコマンドを実行します。
# Cogのインストール
curl -o /usr/local/bin/cog -L https://github.com/replicate/cog/releases/latest/download/cog_`uname -s`_`uname -m`
chmod +x /usr/local/bin/cog
# バージョン確認
cog --version他の環境や詳細なインストール手順については、CogのGitHubリポジトリを参照してください。
プロジェクトディレクトリの作成と移動
mkdir my_sd
cd my_sd
Cogの初期化
cog initコマンドを実行してプロジェクトを初期化します:
cog init
このコマンドにより、cog.yamlとpredict.pyの2つのファイルが生成されます。これらのファイルは、モデルの環境設定と予測インターフェースを定義します。
predict.pyの編集
生成されたpredict.pyを以下のコードで編集します:
import os
from typing import List
import torch
from diffusers import StableDiffusionPipeline
from cog import BasePredictor, Input, Path
class Predictor(BasePredictor):
def setup(self):
"""Load the model into memory to make running multiple predictions efficient"""
print("Loading pipeline...")
# キャッシュディレクトリの設定
self.cache_dir = "diffusers-cache"
os.makedirs(self.cache_dir, exist_ok=True)
# Hugging Face のキャッシュディレクトリを設定
os.environ["TRANSFORMERS_CACHE"] = os.path.join(self.cache_dir, "transformers")
os.environ["HF_HOME"] = os.path.join(self.cache_dir, "hf_home")
os.environ["HF_HUB_CACHE"] = os.path.join(self.cache_dir, "hf_hub")
# 各キャッシュディレクトリを作成
for cache_path in [os.environ["TRANSFORMERS_CACHE"],
os.environ["HF_HOME"],
os.environ["HF_HUB_CACHE"]]:
os.makedirs(cache_path, exist_ok=True)
# Stable Diffusionパイプラインの初期化
self.pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
cache_dir=self.cache_dir,
torch_dtype=torch.float16,
)
# GPUに移動
self.pipe = self.pipe.to("cuda")
# メモリ効率化のための設定
self.pipe.enable_attention_slicing()
def predict(
self,
prompt: str = Input(
description="画像生成のためのテキストプロンプト",
default="a photo of an astronaut riding a horse on mars"
),
negative_prompt: str = Input(
description="画像に含めたくない要素を指定する負のプロンプト",
default="",
),
num_inference_steps: int = Input(
description="推論ステップ数",
ge=1,
le=100,
default=50
),
guidance_scale: float = Input(
description="プロンプトへの追従度",
ge=1,
le=20,
default=7.5
),
num_outputs: int = Input(
description="生成する画像の数",
ge=1,
le=4,
default=1
),
seed: int = Input(
description="乱数シード",
default=None
)
) -> List[Path]:
"""画像を生成して保存されたファイルパスのリストを返す"""
# シードの設定
if seed is not None:
torch.manual_seed(seed)
# 画像生成
images = self.pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
num_images_per_prompt=num_outputs
).images
# 画像の保存
output_paths = []
for i, image in enumerate(images):
output_path = f"/tmp/output_{i}.png"
image.save(output_path)
output_paths.append(Path(output_path))
return output_paths
cog.yamlの編集
次に、cog.yamlを以下の内容に編集します:
build:
gpu: true
cuda: "11.7"
python_version: "3.10"
system_packages:
- "wget"
- "git"
python_packages:
- "--extra-index-url https://download.pytorch.org/whl/cu117"
- "torch==2.0.1+cu117"
- "torchvision==0.15.2+cu117"
- "diffusers==0.19.3"
- "transformers==4.31.0"
- "accelerate==0.21.0"
- "safetensors==0.3.1"
- "huggingface-hub==0.16.4" # バージョンを固定
- "scipy==1.9.3"
- "ftfy==6.1.1"
predict: "predict.py:Predictor"
このファイルでは、使用するPythonのバージョン、必要なパッケージ、システムパッケージ、および予測を行うクラスを定義しています。
Dockerイメージのビルド
以下のコマンドを実行してDockerイメージをビルドします:
cog build
このコマンドは、predict.pyとcog.yamlに基づいてDockerイメージを作成します。
モデルのテスト
Dockerイメージが正しくビルドされたことを確認するために、以下のコマンドでローカルでモデルをテストします:
cog predict -i prompt="cat"

モデルのデプロイ
モデルが正しく動作することを確認したら、Replicateにログインし、モデルをプッシュします:
# ログイン
cog login
This command will authenticate Docker with Replicate's 'r8.im' Docker registry. You will need a Replicate account.
Hit enter to get started. A browser will open with an authentication token that you need to paste here.
If it didn't open automatically, open this URL in a web browser:
https://replicate.com/auth/token
Once you've signed in, copy the token from that web page, paste it here, then hit enter:
# ここで token をペーストします
CLI auth token:
You've successfully authenticated as htakeda777! You can now use the 'r8.im' registry.
# モデルの push
cog push r8.im/username/model-name
ブラウザを起動し、https://replicate.com/auth/token に表示される CLI auth token をコピペしてするとログイン
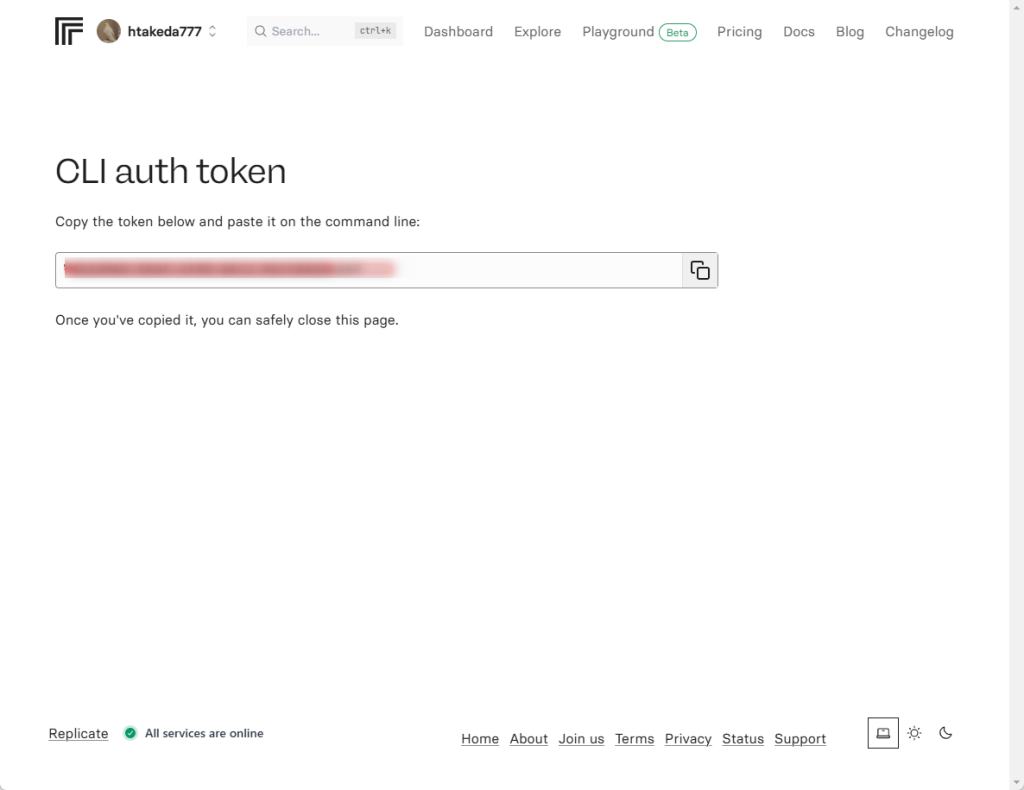
usernameとmodel-nameは、Replicate上でのユーザー名とモデル名に置き換えてください。
モデルの利用
モデルを利用するためには、https://replicate.com/models に行くとPUSHしたモデルの一覧が表示されます。

モデルを選択するとモデルの実行フォームが表示され、プロンプトを入力すると画像が生成されます。
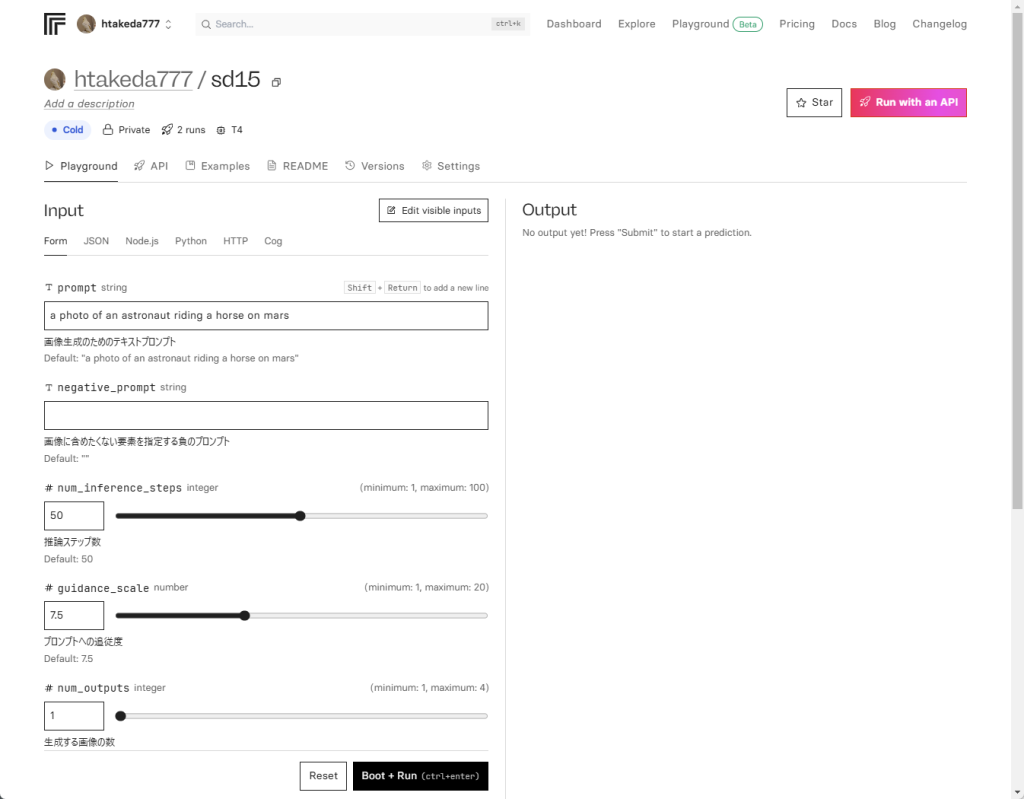

まとめ
コールドスタートによりセットアップに時間がかかり、生成には約10分、コストは0.15ドルかかります。このため、使い勝手が良いとは言えません。ただし、モデルデータを事前に含めてPUSHすることで、起動時間は約4分に短縮できました。とはいえ、オンデマンドで1枚ずつ画像を生成するよりも、大量の画像を生成する用途に適しているようです。
仕事で、AWSのTASKを使ってEC2とECS(AWSのDocker実行環境)上で別のモデルを動かしてみましたが、やはりコールドスタートでは起動に4〜5分ほどかかりました。現時点では、コールドスタート時にセットアップに時間がかかるのは避けられない状況のようです。
Huggingfaceのオープンソースモデルを試しに動かすには、とても良い選択肢です。多くの有名なモデルがpublicで公開されており、ユーザーはこれらのモデルを自由にダウンロードして利用することができます。そのため、すぐに試験的な動作確認やテストを行うことが可能です。特に初期のプロトタイプやモデルの性能評価を行う場合、簡単にアクセスできることから非常に便利です
Follow me!
